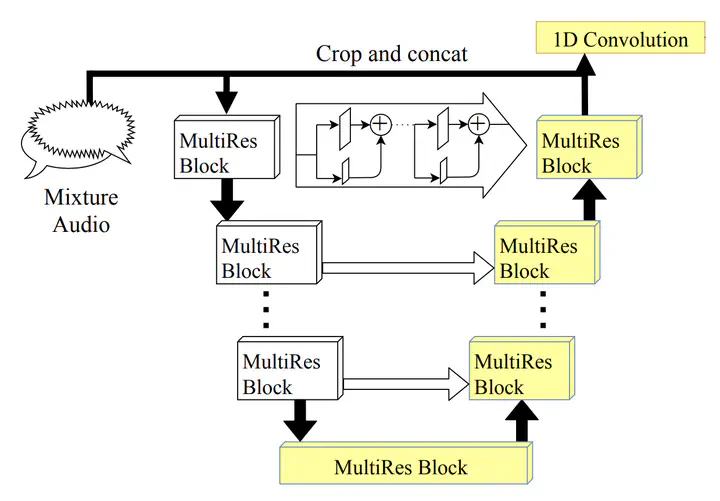
 Architecture of J-Net
Architecture of J-NetAbstract
Several results in the computer vision literature have shown the potential of randomly weighted neural networks. While they perform fairly well as feature extractors for discriminative tasks, there is a positive correlation between their performance and their fully trained counterparts. Based on these discoveries, we pose two questions: What is the value of randomly weighted networks in difficult generative audio tasks such as audio source separation? And does such a positive correlation still exist when it comes to large random networks and their trained counterparts? In this paper, we demonstrate that the positive correlation indeed still exists. Building on this discovery, we can explore different architecture designs or techniques without training the entire model. Moreover, we found a surprising result that, compared to the non-trained encoder (down-sample path) in Wave-U-Net, fixing the decoder (up-sample path) to random weights results in better performance, almost comparable to the fully trained model.
陳柏文 Bo-Wen Chen
Graduate Researcher
My research focuses on machine learning and digital speech processing, specifically in the areas of Text to Speech (TTS) and Automatic Speech Recognition (ASR).