Biography
Bo-Wen Chen is a skilled machine learning researcher with a focus on digital speech processing. Holding a Master’s degree from the Graduate Institute of Communication Engineering at National Taiwan University, he possesses a strong academic foundation under the guidance of Prof. Hung-Yi Lee. Bo-Wen’s expertise lies in exploring novel topics within speech processing and acoustic modeling using deep learning techniques. One of his notable contributions is the development of a duplex speech chain model that facilitates simultaneous Text-to-Speech and Automatic Speech Recognition.
- Machine Learning
- Digital Speech Processing
- Text-to-Speech
- Automatic Speech Recognition
- Computer Architecture
M.S. in Graduate Institute of Communication Engineering, 2018-2022
National Taiwan University
B.S. in Electrical Engineering, 2014-2018
National Taiwan University
Skills
Fairseq, Pytorch, Tensorflow
Kaldi
Text-to-Speech (TTS),
Automatic Speech Recognition (ASR)
Experiences
See Publications for more details.
Supervised by Prof. Hung-Yi Lee
- Conducted research in speech processing and acoustic modeling utilizing deep learning techniques to explore novel topics
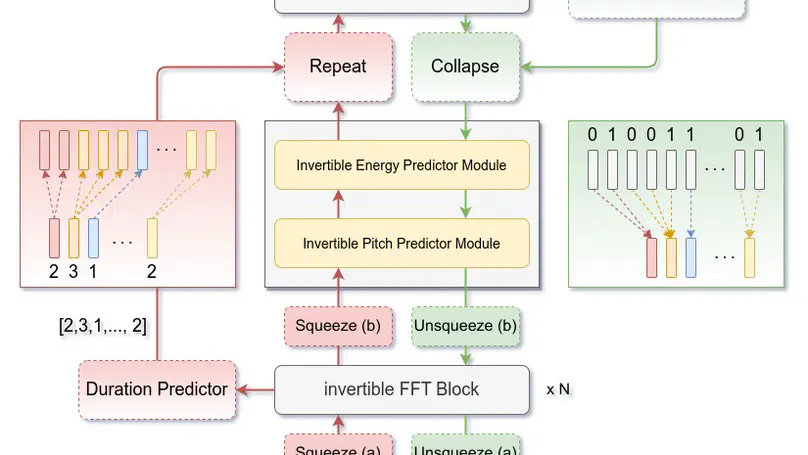
- Proposed the first Duplex Speech Chain model capable of performing Text‑to‑Speech and Automatic Speech Recognition simultaneously through the use of a single reversible network, enabling the effective use of supervision signals from both directions
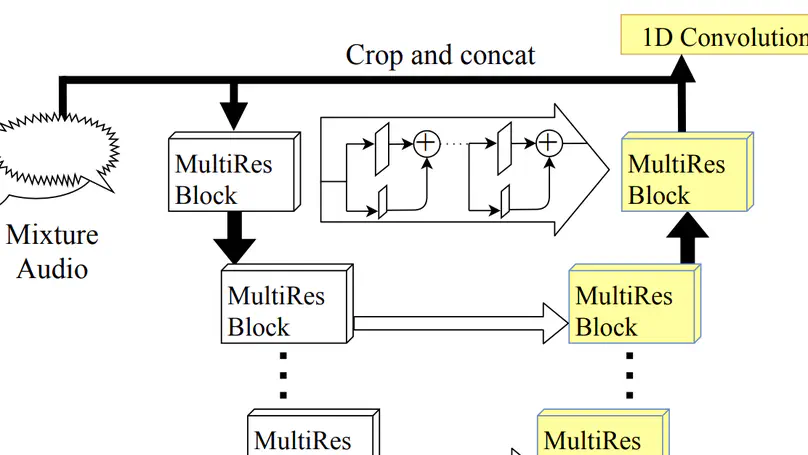
- Proposed an efficient Neural Architecture Search technique for audio source separation, reducing search time by 50% by leveraging on the signal to distortion ratio (SDR) correlation between randomly weighted and fully trained models
- Served as a reviewer for ICASSP 2020
- Compressed acoustic models for compute-constrained embedded systems via Singular Value Decomposition (SVD), sustaining performance with 50% fewer parameters
- Created a toolkit to facilitate seamless migration of acoustic models from Kaldi to Tensorflow, effectively reducing development time
- Reimplemented a super‑resolution model, which predicted the residual between the original image and its super‑resolved counterpart
Featured Publications
Awards
- Achieved 8th place out of 469 teams on the leaderboard as team leader
- Used pretrained language models, SCIBERT, with additional linear layers to perform sequential sentence classification